Sunday 23 February 2025
A team of researchers has developed a new method for improving the efficiency of large language models (LLMs), which are increasingly used in applications such as text generation, coding assistance, and question answering.
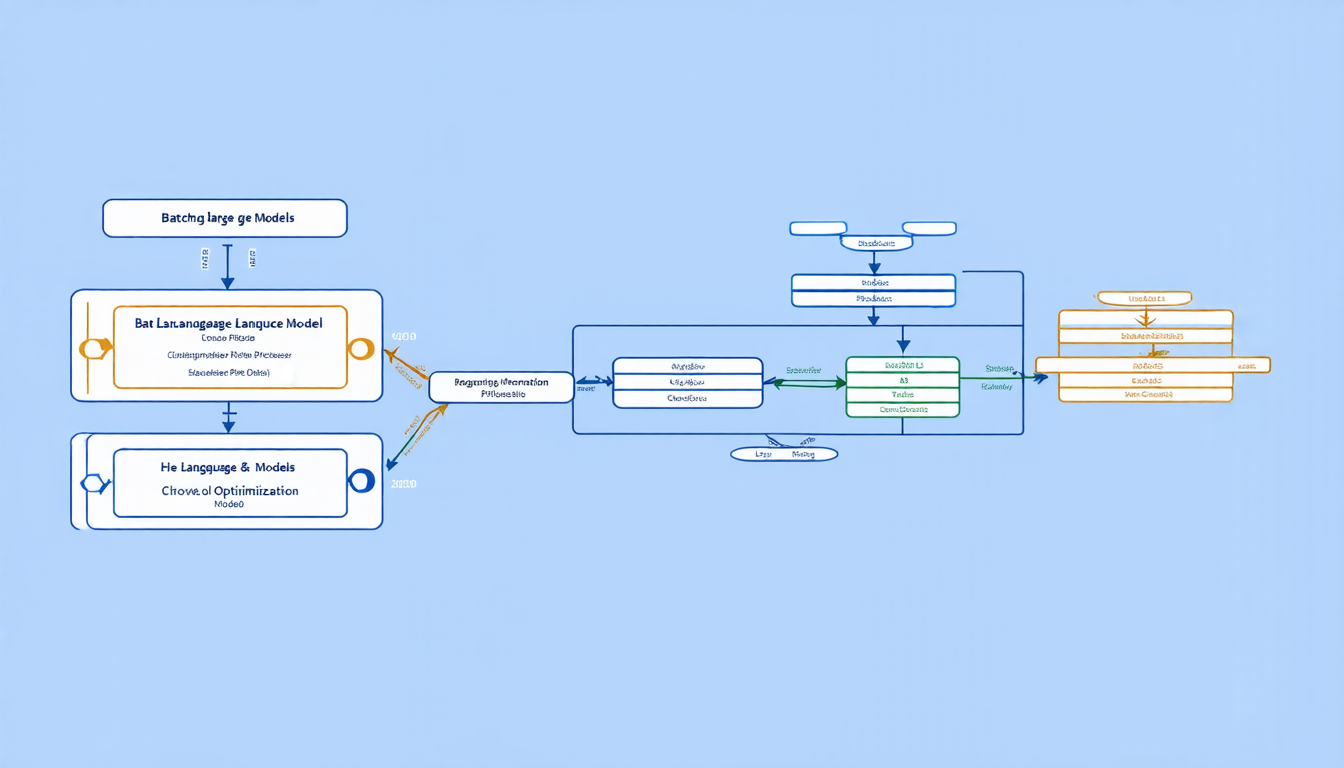
The problem with LLMs is that they can be slow and inefficient, particularly when processing multiple requests at once. One approach to addressing this issue is batching, where multiple requests are processed together in a single batch. However, this method has its limitations, as it can lead to resource underutilization due to the varying lengths of the requests.
To overcome these challenges, the researchers propose a multi-bin batching approach, which involves dividing the requests into smaller groups based on their predicted execution times. The key innovation is the use of a predictor system that estimates the length of each request and assigns it to one of the bins accordingly.
The team tested their approach using a BERT-based predictor and found that it significantly improves the throughput of LLM inference systems. For example, when using 4 bins, they achieved an 8% increase in throughput compared to not batching at all. While this may seem modest, it can have a significant impact on the performance of real-world applications.
The researchers also explored the use of different bin sizes and numbers of bins, finding that increasing the number of bins generally leads to improved throughput. However, they also observed that the accuracy of the predictor plays a critical role in determining the effectiveness of the multi-bin batching approach.
Overall, this study demonstrates the potential benefits of using machine learning techniques to optimize the efficiency of LLM inference systems. By improving the throughput and reducing latency, these approaches can help unlock the full potential of LLMs in a wide range of applications.
In practice, the multi-bin batching approach could be implemented by training a predictor model on a dataset of labeled requests, and then using this model to assign each incoming request to one of the bins. The bin with the shortest predicted execution time would then be selected for processing, allowing the system to take advantage of any available resources.
The researchers believe that their work has important implications for the development of LLMs in areas such as natural language processing and artificial intelligence. By addressing the challenges associated with batching and prediction, they hope to enable the creation of more efficient and effective LLM-based systems that can be used in a wide range of applications.
Cite this article: “Efficient Large Language Model Inference Through Multi-Bin Batching”, The Science Archive, 2025.
Large Language Models, Batching, Predictor System, Bin Sizes, Throughput, Latency, Machine Learning, Natural Language Processing, Artificial Intelligence, Efficiency





