Thursday 11 September 2025
The quest for efficient language models has led researchers to a significant breakthrough, dubbed OverFill. This innovative approach decouples the prefill and decode stages of large language model (LLM) inference, allowing for faster and more accurate processing.
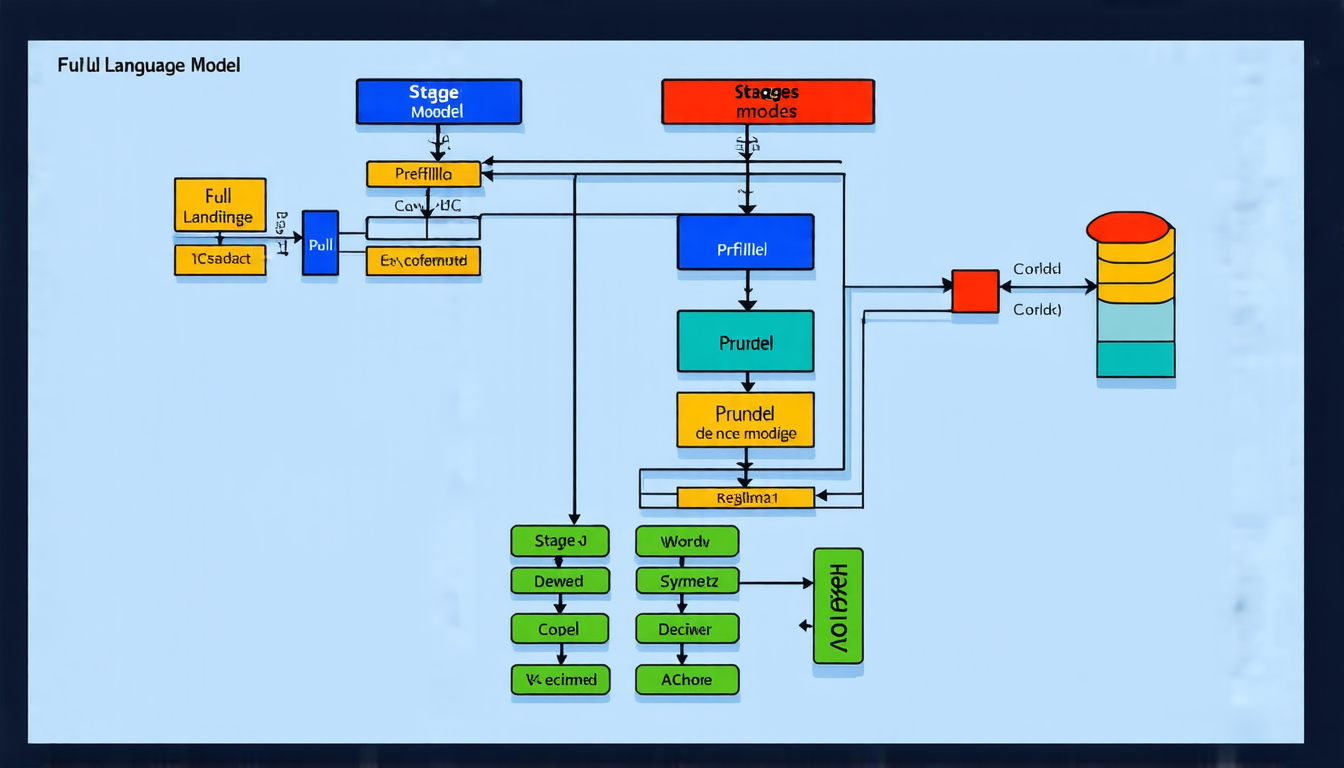
Traditionally, LLMs have been limited by their massive parameter counts, which slow down both computation and memory access. The two-stage process – prefilling and decoding – is where the bottleneck lies. Prefilling involves computing a cache of key-value pairs to facilitate fast lookup during generation, while decoding generates output tokens sequentially.
OverFill addresses this issue by separating these stages into distinct models with different sizes and computational profiles. In the first stage, a full model is used for prefilling, processing input data in parallel to build a comprehensive Key-Value cache. This step leverages more compute resources than the decode stage, which makes it an attractive target for optimization.
The second stage employs a dense pruned model for decoding, generating output tokens sequentially while minimizing memory access and computational overhead. By offloading some of the workload from the full model to this smaller variant, OverFill achieves improved generation quality with minimal latency penalty.
Experiments have shown that OverFill outperforms traditional 1B-pruned models by 83.2% on average across standard benchmarks, such as GSM8K and ARC-challenge. Furthermore, it matches the performance of same-sized models trained from scratch while using significantly less training data.
The benefits of OverFill extend beyond improved accuracy and efficiency. This approach also enables researchers to explore new architectures and design choices without sacrificing computational resources or memory constraints. By decoupling the prefill and decode stages, developers can focus on optimizing individual components, leading to more innovative and effective language models.
While further refinement is needed to fully realize OverFill’s potential, this breakthrough has significant implications for natural language processing and AI research as a whole. The ability to efficiently process massive amounts of data will enable new applications, from conversational agents to text summarization tools, and accelerate the development of more sophisticated language understanding systems.
Cite this article: “OverFill: A Breakthrough in Efficient Language Models”, The Science Archive, 2025.
Large Language Models, Overfill, Prefill, Decode, Key-Value Cache, Pruned Models, Natural Language Processing, Ai Research, Computational Efficiency, Memory Access