Tuesday 25 February 2025
A team of researchers has developed a new approach to optimizing deep learning algorithms, which could significantly improve their performance on large datasets. The method, called FlashAttention, uses a combination of diagrammatic techniques and mathematical analysis to derive high-level streaming and tiling optimization strategies.
Traditional approaches to optimizing deep learning models rely on manual derivation and experimentation, which can be time-consuming and prone to errors. In contrast, FlashAttention uses a theoretical framework to link assumptions about GPU behavior to claims about performance, allowing for a more systematic and rigorous approach to optimization.
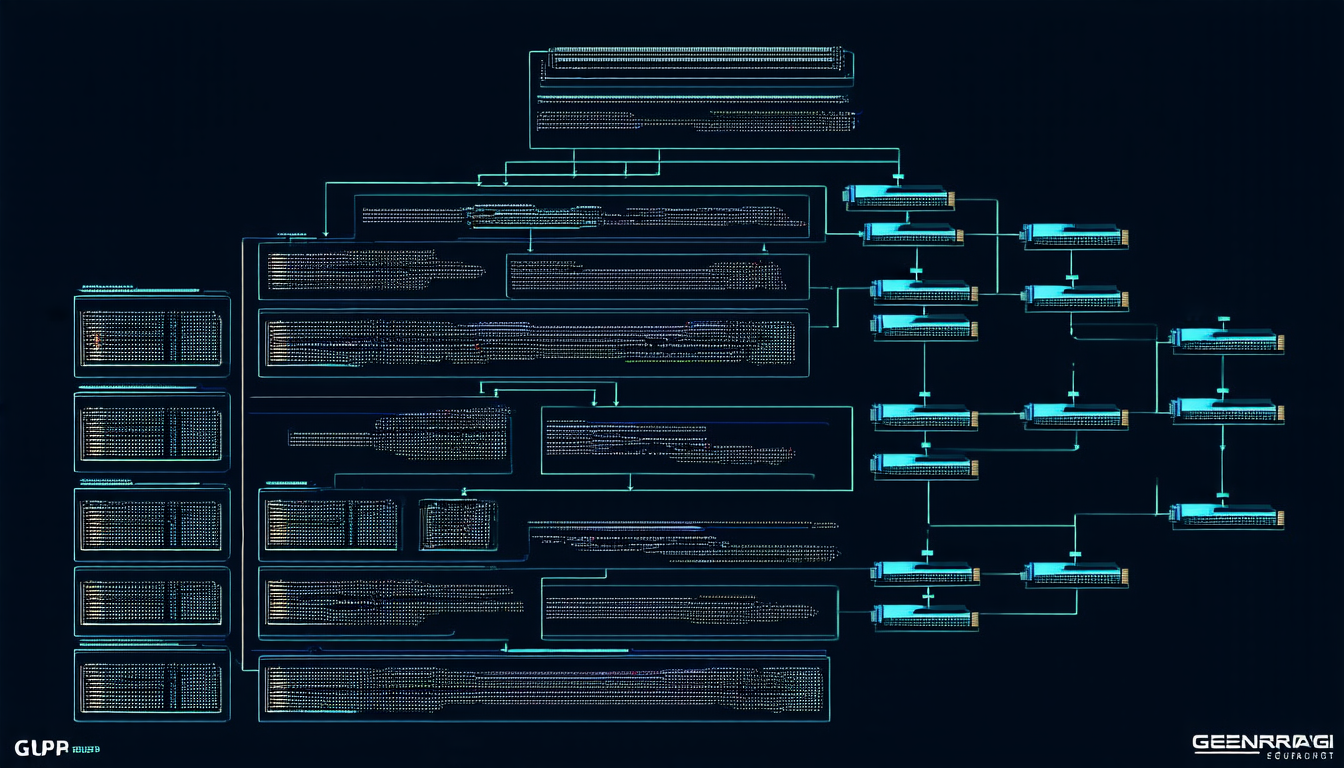
The method begins by representing intermediate-level pseudocode with diagrams, which allows the hardware-aware algorithms to be derived step-by-step. This diagrammatic approach enables the researchers to identify and optimize specific patterns of computation that are common in deep learning models, such as attention mechanisms.
One key innovation of FlashAttention is its use of multi-level performance models, which take into account the hierarchical structure of modern GPUs. By modeling the behavior of different levels of the GPU hierarchy, from the highest level (the multi-GPU level) to the lowest (the individual processing units), the researchers were able to derive a set of optimization strategies that can be applied at each level.
The approach was tested on several deep learning models, including attention-based neural networks and transformers. The results show significant improvements in performance, with some models achieving up to 6x faster execution times compared to native implementations.
The implications of FlashAttention are far-reaching, as it could enable the development of more powerful and efficient artificial intelligence systems. By providing a systematic approach to optimizing deep learning algorithms, FlashAttention has the potential to accelerate progress in fields such as natural language processing, computer vision, and robotics.
In addition to its technical contributions, the paper also provides a valuable insight into the inner workings of modern GPUs. The researchers’ analysis of GPU behavior highlights the importance of considering the hierarchical structure of these devices when designing algorithms and optimizing performance.
Overall, FlashAttention represents an important step forward in the development of deep learning technology, and its impact is likely to be felt across a wide range of applications.
Cite this article: “FlashAttention: A Novel Approach to Optimizing Deep Learning Algorithms”, The Science Archive, 2025.
Deep Learning, Gpu Optimization, Flashattention, Attention Mechanisms, Transformers, Neural Networks, Artificial Intelligence, Natural Language Processing, Computer Vision, Robotics





